[Proposed Method]
- 본 논문은 C3-STISR을 제안
1. triple-clue guided super-resolution
2. triple clues에 대한 추출과 fusion 요소
- 위 1., 2.에 대해 본 논문에서는 소개함
low-resolutionimage $I_{LR} \in R^{CXN}$
C : 각 이미지의 channel의 수
$N = H \times W$ 는 collapsed sparial dimension
[Proposed Method - Overview]
본 논문의 목표 : 입력 LR image $I_{LR}$과 몇몇 text-specific clue $h_t$를 기반으로 $I_{SR} \in R^{C \times (4 \times N)}$ 초해상화 이미지를 만드는 것
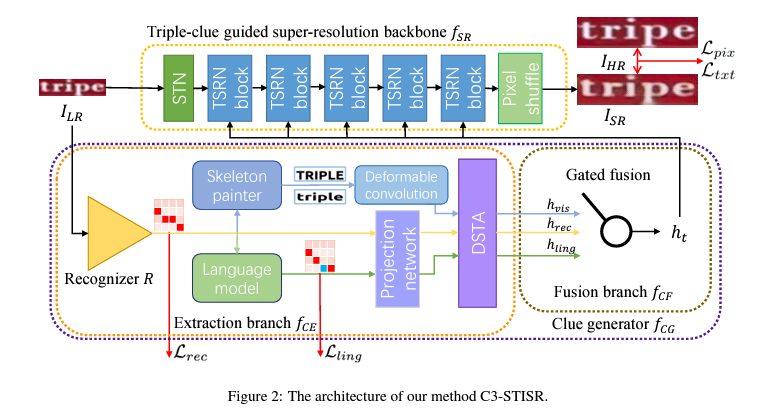
C3-STISR의 아키텍처는 주요한 두 가지 요소가 있음
1. triple-guided super-resolution backbone $f_{SR}$ : super-resolution image $I_{SR}=f_{SR}(I_{LR}, h_t)$를 생성하기 위해 $I_{SR}$과 $h_t$를 가짐
2. clue generator $f_{CG}$ : super-resolution을 안내하기 위한 clue $h_t$를 생성
$f_{CG}$에는 두가지 subcomponents가 있음
1) clue extraction branch $f_{CE}$
- 이는 $I_{LR}$과 함께 recognizer R의 feedback에 대한 인식 단서$h_{rec}$, 시각 단서$h_{vis}$, 언어 단서$h_{ling}$를 생성
: ${h_{rec}, h_{vis}, h_{ling}}=f_{CE}(R(I_{LR})$
2) clue fusion branch $f_{CF}$
- 생성된 삼중 clue를 융합하여 초해상화를 위한 comprehensive clue $h_t$를 생성
: $h_t = f_{CF}(h_{rec}, h_{vis}, h_{ling})$
모델 훈련 동안, 각 훈련된 LR image의 HR image(ground truth)는 pixel을 평가하기 위한 감독과 text-specific losses로 주어짐
[Proposed Method - Triple-clue Guided Super-Resolution Backbone]
1. TextZoom 데이터 세트에서 HR-LR 쌍은 사람이 수동으로 자르므로 여러 픽셀 수준의 offset이 발생할 수 있음. 따라서, 이전 작업에 이어 STN으로 시작
2. $h_t$의 guidance를 따라 $I_{LR}$를 복구하기 위해 5개의 수정된 TSRN Block이 사용됨
3. pixel shuffle 모듈을 적용하여 초고해상도 이미지를 재구성함
4. 두가지 다른 손실 $L_{pix}$, $L_{txt}$는 각 pixel 및 text별 감돌을 제공하는 데 사용됨
L2 pixel loss $L_{pix}$ 및 text focuss loss $L_{txt}$는 trafe-off fidelity와 recognition performance를 위함
$L_{pix} = ||I_{HR} - I_{SR}||_2$
$L_{txt} = \lambda_1a||A_{HR}-A_{SR}||_1 + \lambda_2KL(p_{SR}, p_{HR})$
A : attention map
p : fixed transformer-based rocognizer에 의해 예측된 probability distribution
[Proposed Method - Clue Generator]
이 모듈의 목표 : comprehensive clue $h_t$를 생성하는 것
- triple cross-modal clues(recognition clue $h_{rec}$, visual clue $h_{vis}$, linguistical clue $h_{ling}$)를 분할 정복 방식(divide-and conquer manner)으로 추출
- 그리고, 이를 융합하여 $h_t$ 출력
1. Clue Extraction Branch
1) $h_{rec}$ extraction
- recognizer $R$에 의해 예측된 probability distribution으로 부터 계산됨
$h_{rec}=f_{rec}(R(I_{LR}))$
$R(I_LR) \in R^{L \times |A|}, h_rec \in R^{C' \times N}$
- $C', L, |A|$ : hidden state의 channel 수, 최대 예측된 길이, 알파벳 $A$의 길이
- $f_{rec}:=R^{L \times |A|} \rightarrow R^{C' \times N}$ 는 pixel feature map에 probability distribution $R(I_{LR})$을 변형하는 processing network이며, 불특정 정보를 마스킹 함으로써 error reduction을 수행함
- processing network은 projection network(batch normalization, bilinear interpolation 포함)과 deformable spatiotemporal attention (DSTA) block을 통해 설명됨
- DSTA block : 불특정한 정보를 마스킹하기 위해 spatial attention map을 계산하는 powerful deformable convolution을 이용함
- recognizer의 성능이 $h_{rec}$에 크게 영향을 미칠 수 있음을 고려해 인식기 R을 fine tune하기 위해 distillation loss를 채택함
$L_{rec} = k_1||R(I_{LR})-R(I_{HR})||_1 + k_2KL(R(I_{LR}), R(I_{HR}))$
2) $h_{vis}$ extraction
- 예측된 확률 분포 $R(I_{LR})$가 주어졌을 때, visual clue 추출의 목적은 I_{LR}의 인식 결과로 부터 유도된 텍스트 이미지의 시각적 정보를 생성하는 것
- decoding function $f_{de}:=R^{L \times |A|} \rightarrow N^L$은 확률 분포를 텍스트 문자열로 디코딩한 다음 text image를 - 그리기 위해 skeleton painter $f_{sp}:=N^L \rightarrow R^{C \times N}$를 활용함
- 그려진 텍스트 이미지는 인식한 텍스트의 골격을 나타냄
---
뒷 내용 추후 작성


