◎ Linear Regression : 선형 회귀

[그림 1]을 수식으로 나타낸다면 y=ax+b이다.
y는 세로축, x는 가로축, a는 기울기, b는 절편이다.
[그림 1]의 식은 선형 회귀에 적용할 수 있다. 어떠한 값을 선형 회귀로 구하고자 한다면 그 수식은 H(x)=Wx+b이다.
H(x)는 x에 다른 Hypothesis(가설), W는 가중치, b는 편향이다.

선형 회귀를 통해 값을 예측하다 보면 [그림 2]와 값은 그래프가 그려진다.
[그림 2]에서 파란색이 우리가 얻고자 하는 값(예측값)이고, 빨간색 점이 선형 회귀를 통해 얻은 실제 값이다. 빨간색 선은 얻고자 한 값과 실제 값의 차이(H(x)-y)이다.
[그림 2]와 같이 얻고자 한 값과 실제값의 차이가 양수/음수 모두 나올 수 있다.
이렇게 다양한 차이 값들을 그대로 합하면 error의 값을 구하는 것이 무의미해진다.
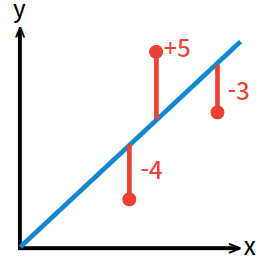
[그림 3]과 같이 에러 값들이 -4, +5, -3이라고 하자. 이들은 평균적으로 절댓값 4 만큼의 에러를 보이고 있음을 알 수 있다. 하지만, 에러 값들을 그대로 합한다면 -4+(+5)+(-3)=-2 가 나온다. 이는 에러 값을 무의미하게 만든다는 것을 보여준다.
따라서, Machine Learning에서는 나온 각 각의 error값들을 제곱해서 사용한다. 제곱한 값을 바탕으로 우리는 비용 함수를 구할 수 있다.
전체 error 값들의 평균적인 값을 알기 위해 사용하는 것을 비용 함수라고 한다.
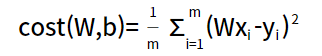
Machine Learning의 학습 목표는 [그림 4]와 같은 비용 함수를 최소화시키는 것이다.
*부스트 코스 강의 학습 내용입니다.
'STUDY > 인공지능' 카테고리의 다른 글
| [기초 ML] Gradient descent algorithm (0) | 2022.02.07 |
|---|---|
| [실습 ML] Simple Linear Regression (0) | 2022.02.03 |
| 나를 위한 아나콘다 사용법 정리 (0) | 2022.01.24 |
| [Andrew Ng] 로지스틱 회귀 (0) | 2022.01.12 |
| [Andrew Ng] 딥러닝 1단계 : 신경망과 딥러닝 (0) | 2022.01.12 |


