안녕하세요. 오늘 리뷰할 논문은 "Found a Reason for me? Weakly Grounded Visual Question Answering using Capsules" 입니다. 이 논문은 2021년 CVPR에서 발표된 논문입니다! 원본 링크는 아래 링크를 참고해주세요!!
1. What is VQA?
본 논문에서 다뤄지는 작업은 VQA입니다.
- VQA란? Visual Quesion Ansering의 준말로, 입력으로 이미지와 질문쌍이 들어왔을때 이에 올바른 정답을 나타내는 작업을 말합니다.

다시말해, 위 그림과 같이 이미지에 대한 질문 "Are the black horses to the right of the vehicle on the road?"이 들어왔을때 질문에 대한 올바른 답안 "Yes"를 도출해내는 작업입니다.
이전의 VQA은 올바른 정답인지 아닌지를 도출해내는 VQA accuracy에만 중점을 맞추었다면 최신 VQA들은 정답의 기반이 되는 grounding accuracy에도 중점을 두어 많은 연구를 진행하고 있습니다.
이러한 grounding accuracy의 기준은 다음과 같이 이루어집니다.
- 주어진 답안에 대한 이미지 각 각의 attention map을 고려한다.
- 정답과 관련된 객체의 attention을 평가한다.
대부분 VQA 모델들은 grounding accuracy를 달성하기 위해서 pretrained object detection model에 의존합니다. 이러한 pretrained모델에 의존하면 MS COCO같은 객체 클래스 범위로 제한됩니다. 그리고 이러한 pretrain을 위해서는 관련 객체에 대한 영역 annotation을 달아야 합니다. 이러한 과정을 실제 대규모 어플리케이션에서는 많은 제한을 가져옵니다.
따라서, 본 논문은 pretrained object detection model에 의존하는 기존 VQA에서 VQA supervision기반의 weakly supervised visual grounding을 사용합니다. VQA supervision기반의 weakly supervised visual grounding은 아래와 같습니다.
- 시각적인 질문에 대한 정답들과 올바른 시각적 증거를 VQA 작업들안에서만 학습합니다.
- object level information을 입력과 감독으로 사용하지 않습니다.
2. Main Contribution
본 논문의 주요 contribution은 아래와 같습니다.
- VQA frameworks에 CapsuleNetwork를 적용할 것을 제안하였다.
- Soft Masking을 사용할 것을 제안하였다.
- CLEVR dataset을 확장한 CLEVR-Answer dataset을 제안하였다.
Contribution 1은 weakly supervised learning의 주요 작업인 1) 관련 인스턴스 찾기, 2) 인스턴스 사이의 관계 모델링 하기를 해결하기위해 제안되었습니다.
Contribution 2는 weakly supervised learning의 감독 부족 문제로 인해 일부 캡슐이 선택되지 않는 문제를 해결하기위해 제안되었습니다.
Contribution3은 답변의 visual basis를 위해서 제안되었으며, MAC과 Stacked NMN 테스트를 위해 쓰여집니다.
3. Datasets
논문의 데이터 셋으로는 GQA와 CLEVR-Answers 두가지가 있습니다.
GQA 데이터 셋은 다음과 같은 특징을 지닙니다.
- 113K image, 22M QA 쌍으로 구성되어있습니다.
- object annotaion에서 unpretrained 기능을 사용하면서 weakly supervised tasks에 대한 기준점을 제공합니다.
- multi-hop reasoning questions와 함께 시각적인 참조를 위한 데이터 셋입니다
- VQA의 grounding accuracy 평가 집중되어 사용됩니다.
- object detection supervision없이 MAC의 grounding accuracy 평가에 사용됩니다.
CLEVR 데이터 셋을 다음과 같은 특징을 지닙니다.
- 70k image와 700k QA으로 구성된 훈련 세트, 15k image와 150k QA으로 구성된 검증 세트, 15k image와 150k QA으로 구성된 테스트 세트가 있습니다.
- GQA 데이터 셋과 반대로 합성적인 이미지가 사용됩니다.
- 시각적인 참조를 위해 bounding box를 제공합니다.
CLEVR-Answers는 CLEVR 데이터셋 에서 확장된 데이터 셋으로 아래와 같은 특징을 지닙니다.
- 답변에 대한 시각적 근거를 위해 CLEVR 데이터 셋에서 확장된 데이터입니다.
- 이것은 답변에 대한 객체의 올바른 bounding box를 제공합니다.
- ground truth bounding box는 훈련 중에는 사용되지않고 평가에서만 사용됩니다.
4. Related Work
본 논문과 관련된 작업으로는 CapsNet이 있습니다.
- CapsNet이란? Capsule Network로 이미지에 대한 view equivariation 특징 벡터 학습을 위해 제안된 네트워크입니다.
- 기존 CNN에서 사용되는 Pooling Layer의 문제를 보충하기 위해 Dynamic routing을 사용한 CapsNet이 제안되었습니다.
기존 CNN에서 사용된 Pooling Layer는 많은 한계점을 가지고 있습니다.
- 주요한 특징만을 뽑아내는 정보 요약으로 인해 정보 손실이 발생할 수 있습니다.
- 고유 좌표 프레임이 없다는 점에서 생물학적인 형태인식을 위반합니다.
- 등분성 대신 불변성을 제공합니다.
- 이미지간의 많은 변화의 기반이 되는 linear manifolds를 무시합니다.
반면에, CapsNet의 Dynamic routing은 캡슐이 벡터로 이루어졌기에 observation에 대한 observation probabilities와 poses를 결합하는 것을 가능하게 합니다. 이러한 CapsNet의 각 Capsule은 entity(객체)와 property of entity(객체의 행동,속성)을 포함합니다.
이를 통해 CapsNet은 "high-dimensional space"에서 spaces와 layers의 관계를 표현하는 것이 가능하게 해줍니다.

위 그림을 통해 CapsNet을 살펴봅시다.
- MNIST 데이터 셋을 입력으로 넣어줍니다.
- Convolutional Layer(9X9X256)을 거칩니다. 20X20X256의 출력이 나옵니다.
- Convolutional layer(9X9X32X8)을 한번 더 취해 Primary Caps를 구해줍니다.
- Primary Caps를 [6,6,32X8]->[6X6X32,8,1]로 feature map을 reshape해줍니다. reshape를 통해 각 캡슐은 8개의 property를 가지게 됩니다. 이를 통해 8 property를 가지는 1152(6X6X32)개의 캡슐을 생성하게 됩니다.
- Dynamic rounting을 통해 상위캡슐과 연결시켜줍니다. 최종 10개의 캡슐을 생성하게 됩니다. 이것은 16 property를 나타내는 벡터 요소입니다.


routing algorithm을 자세히 살펴보면 위와 같습니다.
알고리즘의 입력으로 primary caps와 digit caps의 가중치 행렬 ^Uj|i(8X16)과 primay Caps인 L을 넣어줍니다. r은 routing 알고리즘의 반복 횟수입니다.
- Primary caps와 Digit caps를 연결해주는 bji는 0으로 설정해줍니다.
- bi에 softmax를 취해 primary caps Cj에 넣어줍니다. softmax방정식은 Equation 3과 같습니다. 이 Dynamic routing process는 합이 1이 되도록 만들어줍니다.
- Cij를 가중치 행렬^Uj|i과 곱해주어 Digit Caps의 벡터길이와 같게 만들어줍니다.
- 3에서 구한 Sj를 squash()하여 capsule에 non-linearity가 추가되도록 합니다. 이를 통해서 우리가 최종적으로 알고자하는 entity의 존재 확률을 0~1사이의 값으로 표현해줍니다. 자세한 부분은 Equation1을 통해 알 수 있습니다. Equation에서 각 element들은 property of entity를 나타내고 L2 norm은 property of entity의 존재를 나타냅니다. 이 수식의 값이 작으면 0에 가깝게 설정하고, 값이 크며 1에 가깝게 설정해줍니다.
- 4에서 구한 특징 벡터Vj을 가중치행렬 ^Uj|i과 곱하여 agreement를 취한 후 bij에 더해 update를 시켜줍니다. 이를 통해 한번의 Dynamic routing 과정이 끝나게 됩니다. 이를 r 번 반복하여 최종 Vj를 구하면 됩니다.
5. Proposed method
본 논문에서 제안한 방식의 전체적인 파이프라인은 아래 그림과 같습니다.

위 파이프라인의 동작과정은 다음과 같습니다.
- 질문이미지쌍이 입력으로 들어오면 이미지는 이미지 인코더를 통해 이미지 특징 X를 얻습니다. 그리고 질문은 RNN을 사용하여 질문특징(fs, fw)를 얻습니다.
- 이러한 질문 특징은 T개의 텍스트 쿼리를 생성하는 multi-hop reasoning module에 입력됩니다.
- Primary Capsule은 Conv feature를 Capsule로 변환하고 routing by agreement알고리즘인 EM rounting을 사용합니다. 이 Capsule은 추론 과정 내에서 시각적으로 표현하는데 사용합니다.
- 각 시간 단계 t에서 softmasking은 qt를 사용해 관련없는 캡슐을 마스킹합니다. Vmct로 표시된 각 공간 위치에서 캡슐의 하위 집합을 선택합니다.
- 선택된 캡슐에 대해 reasoning step을 수행합니다. 여기서 출력은 벡터 형태로 생성됩니다.
- Output module은 이러한 출력을 집계하고 답을 예측합니다. 여기서 생성된 attention map을 후처리하여 grounding prediction을 얻습니다.
(4번 과정 보충)
위 동작 과정 중 4번에 대해 자세히 설명하겠습니다.

- 이것은 질문기반으로 개별 캡슐을 선택합니다. 이러한 캡슐 선택은 추론 작업과 관련없는 capsule을 masking합니다. end-to-end방식으로 마스킹할 캡슐을 학습합니다.
- end-to-end방식은 위 그림의 reaoning step을 통해 이루어집니다. 주어진 쿼리에 대한 각 캡슐유형의 관련성을 나타내는 C2 logit set를 생성합니다. 이렇게 생성된 logit set인 m_tlogits는 argmax()를 통해 원핫마스킹을 취해줍니다. 원핫마스킹 후 visual calsule layer에 적용해줍니다.
- qt에 마스크된 visual capsule mt와 visual calsule layer의 출력 Y_c2를 마스킹을 취해 Vmct를 구합니다.
3번까지가 Hard masking과정입니다. 이는 weakly supervised 기반으로 진행되는 본 논문에서는 일부 캡슐이 선캑되지 않는 문제를 발생시킵니다. 이를 해결하기 위해 argmax()부분을 softmax()로 수정하여 soft masking을 취해줍니다. 이를 통해 모든 캡슐에 gradient가 흐를 수 있게 됩니다.
(6번 과정 보충)
6번과정에서 진행한 후처리에 대한 보충 설명을 하겠습니다.
Capsule layer가 답변에 대한 근거 증거가 없을 때 배경 영역을 포함하여 이미지의 다양한 시각적 신호에 attention을 취합니다. 그리고 배경에 대한 attention을 억제하기 위해 불투명 매개변수인 α를 도입합니다. 이를 사용해 공간 attention 후처리 후, attention 임계값 0.5를 적용하여 attention이 높은 이진 마스크를 획득합니다. 이러한 이진 마스크로 연결된 부분을 객체 감지로 간주합니다.
6. Experimental Results
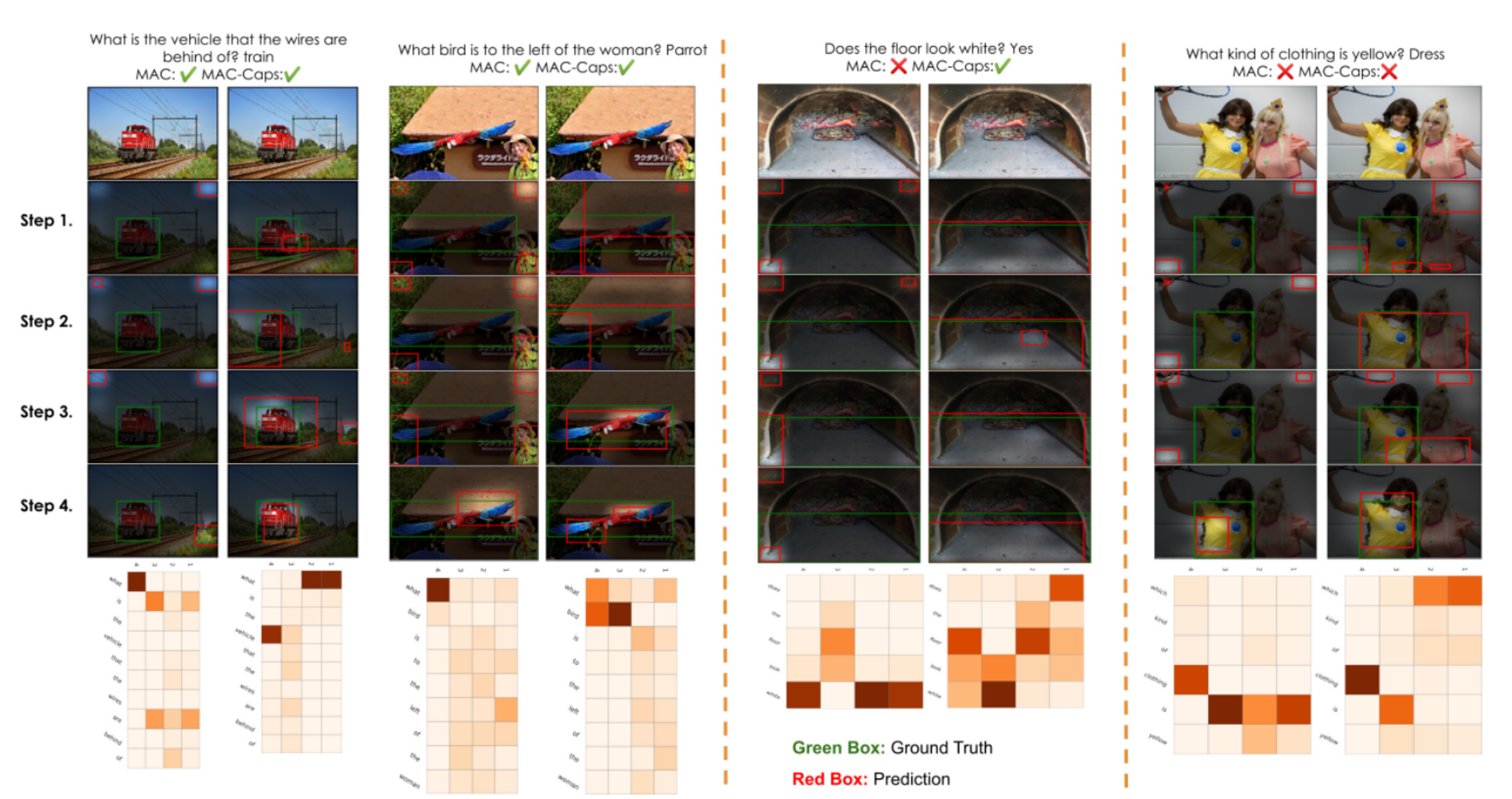
필자는 시각적으로 보기 좋은 qualitiative results만을 들고 왔습니다.
이 실험 결과는 GQA 데이터 셋에서 테스트가 진행되었으며, MAC 프레임워크에 CapsNet을 적용하여 MAC과 비교한 결과입니다.
결과를 보면 CapsNet을 씌우지 않은 프레임워크는 답변의 기반이 되는 gorunding을 모르는 상황에서는 모서리 부분부터 객체 감지하는 것을 볼 수 있습니다. 점차 step이 지날 수록 gorund truth box와 가까워지는 것을 볼 수 있습니다.
CapsNet을 적용한 프레임워크는 답변의 기반이 되는 gorunding을 모르는 상황에서도 ground truth box와 가깝게 객체 감지를 하는 것을 알 수 있습니다.
이를 통해 본 논문에서 제안한 Capsule을 적용한 Weakly grounded VQA는 좋은 성능을 띄는 것을 알 수 있습니다.


